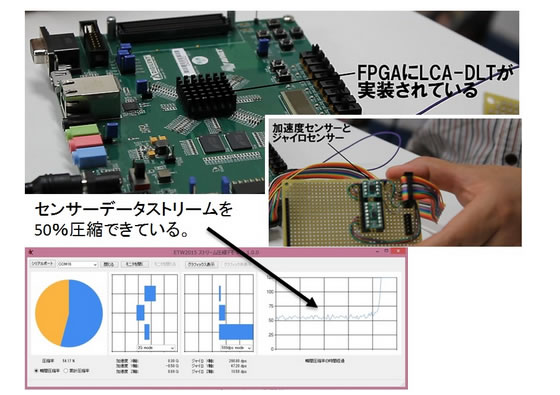
The LCA-DLT compression module cannot compress a symbol to a bit string shorter than the original symbol dynamically. Even if a simple data pattern (for example, all 0s) is entered, it cannot be compressed to a unit smaller than the symbol. This weakness has been a problem from the beginning of research on stream data compression. The problem has been addressing with the development of LCA-DLT. Finally, we have developed a new method ASE Coding (Adaptive Stream-based Entropy Coding) to solve the problem. Read More
Shannon’s information entropy was used as a hint to make the compressed data be a variable length. In the entropy, the number of bits representing the entire data is obtained by taking the sum of the appearance probabilities of symbols. On the other hand, in LCA-DLT, when the average of the sections with a stream is calculated for the number of entries used in the conversion table when compressing a symbol with a stream, it gradually approaches the average amount of Shannon’s entropy in the same section. In the other words, an arbitrary local amount of information (the number of bits representing data) of the data stream can be expressed in the state of the conversion table, and the amount of information is less than or equal to the number of bits representing all symbols. Using this characteristic of the amount of information, we have developed ASE Coding that can compress and decompress the data stream without delay.
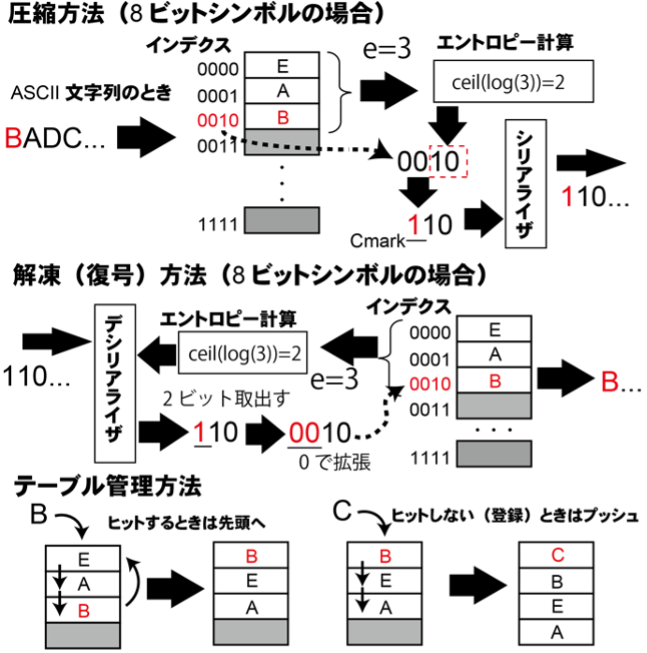
The compressor consists of a look-up table, entropy calculation, and serializer. Comparing the registered symbol, the look-up table pushes to the top if it does not hit. When it hits, it moves the entry to the beginning and pushes others so that the registered or hit symbol is always placed in the top. If a symbol hits in the table, it can be compressed and the compressed symbol is converted by the index of the table. Furthermore, the number of bits of the index is reduced by entropy calculation. Pseudo-entropy is obtained by calculating the above.
For example, as shown in the figure on the right, when the number of tables is 16, the index width is represented by 4 bits. But since the number of entries used is 3, it can be represented by the lower 2 bits of the index. A Cmark bit is added to this compressed symbol, and the compressed symbol is composed of a total of 3 bits and passed to the serializer. The serializer converts the bit width of the output of the compressor and outputs it to the transmission line. The decompressor consists of a deserializer, entropy calculation, and conversion table, and operates in the same way as a compressor. The deserializer receives data with the bit width of the transmission line, and the first bit is the Cmark. Therefore, if it is 0, the following symbol width is received and registered in the table. When it is 1, the entropy calculation is referred to. The number of bits equal to the result of the entropy calculation is received. And, 0 is padded in the upper part of the bits. The index used to search the look-up table. Finally, the symbols from the table are outputted from the decompressor as the original data.
As described above, ASE Coding can perform compression / decryption without stopping the flowing data stream, and can compress to a bit string shorter than the symbol of the data stream, and can be compressed with a variable length. Furthermore, both the compressor and decompressor can be compactly implemented in hardware and work at high speed.
Taiki Kato, Shinichi Yamagiwa, Koichi Marumo. Performance Enhancement of Stream-Based Decompression Process by Notifying Compression Buffer Size, 2023 IEEE Symposium on Computers and Communications (ISCC), 491-494, (2023-08-28), DOI:10.1109/iscc58397.2023.10218261
Shinichi Yamagiwa, Eisaku Hayakawa, Koichi Marumo. Adaptive entropy coding method for stream-based lossless data compression, Proceedings of the 17th ACM International Conference on Computing Frontiers, 265–268, (2020-05-11), DOI:10.1145/3387902.3394037